Network Portal Detection
Shill, the connection manager for Chromium OS, attempts to detect services that are within a captive portal whenever a service transitions to the ready state. This determination of being in a captive portal or being online is done by attempting to retrieve the webpage http://clients3.google.com/generate_204. This well known URL is known to return an empty page with an HTTP status 204. If for any reason the web page is not returned, or an HTTP response other than 204 is received, then shill marks the service as being in the portal state.
Many, or perhaps most, captive portals found in Hotels, Coffee Shops, Airports, etc, either run their own DNS server which returns IP address for all queries which point to their webserver, or they intercept all HTTP web traffic and return a 302 (redirect) response. The captive portal detection works very reliably with these types of portal to indicate that the service is not fully online.
Other captive portals, sometimes run by cellular carriers, provide absolutely no IP connectivity other than to their own servers, but they use a standard DNS server and do not intercept HTTP requests. When a ChromeBook connects to this type of network, the HTTP requests fail because the TCP connection to clients3.google.com can never be established. The portal code tries multiple times for up to 10 seconds to connect to clients3.google.com. If it cannot connect it marks the service as being in a captive portal. This determination is somewhat unreliable because very high latency connections, lossy connections and other network issues can also result in failure to connect to clients3.google.com. All of these are indicative of a network that is not fully functional, but they do not necessarily indicate that the machine is stuck in a captive portal.
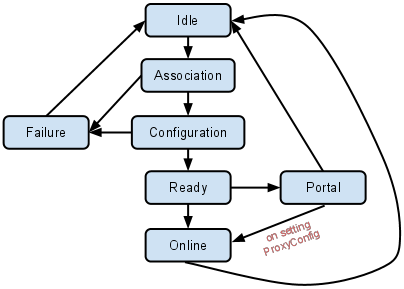
Shill Service State Machine
Reverse Path Filtering
By default ChromeOS enables reverse path filtering in the kernel which drops packets received over a network interface inconsistent with the outbound routing tables. This can present a problem when trying to determine portal state when connected to multiple networks (WiFi, Wired Ethernet and/or a Mobile Broadband connection). To avoid dropped packets, shill disables reverse path filtering globally and on a per device basis while it is running the portal detection code.
Shill Implementation
shill attempts to determine the portal state whenever a service transitions to the ready state. It does the determination using libcurl. Several options are set:
- libcurl is instructed not to cache DNS entries, and not to allow re-use of HTTP connections
- libcurl is given a 10 second timeout for connection and for the entire transaction.
- libcurl is told to bind to a specific interface so all traffic is done over that interface
- libcurl is explicitly told which name servers to use for name resolution
- reverse path filtering is disabled (see above).
Portal detection can be enabled or disabled on a per service basis, or if that is not set (set to AUTO), the determination is done based on the default for the technology.
Interpretation of Portal State
Chrome and shill use portal state for a variety of reasons.
For prioritizing connections shill always prioritizes an online connection over one in a portal state. To the extent that connections using a web proxy are never marked as portal but instead immediately marked as online this inhibits shill's ability to choose the best connection/service.
For cellular connections, and especially for Verizon, Chrome uses portal state to determine when to put up toast which will prompt the user to buy more data. It also controls the presence of a 'buy data' button on the network settings/information tabs for the Verizon Wireless service.
When at the OOBE pages and the login screen, Chrome uses the portal state to prompt the user to check the network connection (more details needed from the Chrome team).
Web Proxies
Web proxies present multiple problems for portal state determination. libcurl supports forwarding requests via a proxy, but this can only be done if the IP address of the proxy is known. Shill does not currently know the IP address of the web proxy, nor does it have the ability to evaluate the URL against the JavaScript code that determines if the proxy should be used.
Several services (e.g. auto update, etc) use Chrome as the engine to fetch URLs, or use Chrome to evaluate the URL and find out which, if any, proxy to use. This seems like an appealing solution, but, knowing the proxy is insufficient, because one might also need to authenticate to the proxy. It is unclear if Chrome exposes the proxy authentication information. I also do not believe that Chrome can proper evaluate a URL relative to the proxy settings on a per interface basis. Chrome almost certainly uses the default connection and the proxy settings for the default connection when doing HTTP requests and when evaluating a URL against the JavaScript configuration.
Future Ideas
- Improve Chrome to be able to do what libcurl does --- route http requests via a specific interface and use the DNS servers associated with that interface.
- Improve Chrome so that it can authenticate to two different proxies on two different interfaces simultaneously.
- Improve Chrome so that it can figure out automatic proxy configuration based on DNS lookup of wpad over different names on different interfaces. (etc....)
- Have the ChromeOS connection manager ask Chrome to fetch the URL instead of libcurl.
Or
- Do much of the above, but have Chrome return proxy authentication as well as IP address for a given URL, so that shill can pass the proxy information to libcurl (or implement it all ourselves in shill).