Source Code Management
Abstract
- Chromium OS is an open source project with the goal of keeping good relationships and communication with upstream sources. Chromium OS is thus structured to upstream code early and often.
- Chromium OS will use Git as its version control system, Rietveld for code reviews and gclient for package checkout management.
This document outlines the Chromium OS process for managing the upstream bits that make up the Chromium OS Linux distribution.
Background
Chromium OS is an open-source project, built for people who spend most of their time on the web. Chromium OS is currently made up of 190 or so open-source packages.
Requirements
Sources hosted by us. Upstream mirrors can be rearranged: sources can be moved, removed, or modified. We also need the sources locally since we need them in order to build. One format. The upstream sources may be stored in any number of version control systems (VCS). Or they may not even be stored in a VCS and instead be available as a tarball, .deb, or .rpm. For our hosted sources, we'd like to have them stored in one VCS format. This may require import from a VCS into our VCS. Alternatively, we could store sources in their native VCS but this would require our developers to work with multiple VCSs. Avoid patch files. Patch files are difficult to maintain and difficult to keep in sync with upstream. We plan to keep a copy of the entire upstream source tree in a VCS.
Simple upstreaming. We want to upstream early and often to minimize the set of changes we have to maintain. We also want a good partnership with upstream. Simple tracking. It needs to be easy to track what bits we've added to open-source components. It should also be easy to track the upstream status of our changes: Has the patch been sent upstream? Has it been accepted, rejected, or accepted in modified form?
Design objectives
Upstream package database. We need a database that stores metadata about each package we are using: homepage, upstream repository information, upstream bugs database location, mailing list, license, upstream submission process, and so on. Examples: fedora, debian, ubuntu, gentoo.
Distributed Version Control System (DVCS). Without a DVCS, distributed development (working with upstream) is difficult. With a DVCS, cloning, merging, and pulling in upstream changes are common operations. For a traditional VCS, cloning an upstream repository involves initially using rsync to copy the upstream repository (assuming such access is given) and then special scripts to handle future pulls.
Each package in its own repository. Pulling multiple upstream trees into one monolithic tree is difficult. It would also make it nearly impossible to use a DVCS. We want to make it easy to work with upstream, easy to track ancestry of our code, and easy to track what patches we've applied. This is hard to do with a monolithic repository. With a repository per package, a simple invocation of the VCS tool's diff will do.
One DVCS tool. We could mirror each upstream repository locally in its native VCS but then we wouldn't be able to use a DVCS where upstream is not. Also, it would force our developers to have to deal with many different VCS tools. We could write our own wrapper library but that's extra development effort we should be able to avoid. Instead, we should just mirror in our one DVCS format, sources which are managed upstream with a different DVCS.
A DVCS with good import/export capability. Many of the most popular DVCS tools support import and export to other backends. The DVCS will support checkin and checkout of code to and from a different backend. Often the import/export is seamless enough that the workflow for dealing with a different backend is not much different from the normal workflow.
Commit log metadata. For some modules, we will be merging in patches from different sources. For such patches, we will annotate the commit log with metadata which documents the original source.
Detailed design
Version control system
Out of all the available DVCS tools, Git implements our design objectives best. Also, of the projects we use which use a DVCS, most use Git.
Our process for managing source repositories will be as follows:
- We will host a Git repository for all source components which we are modifying.Whenever a new package or dependency is added, a new Git repository will be created.
- For upstream Git sources, our repository will be a clone of upstream.
- For upstream sources not stored in Git, we'll create an additional
Git repository.
- The import repository will be named <project>-import.
- For example, project foo would be: foo-import
- Our Git repository will be "based" on the import.
- We will automatically re-sync the import repository with upstream on a regular basis (for example, daily).
- The import repository will be named <project>-import.
- For sources which are not hosted in a VCS upstream, we'll create an
additional Git repository. Typically this will come from a tarball,
deb package, or rpm package.
- The repository will contain the unpackaged source tree.
- Any patches held in the package will be applied as subsequent changes in Git.
- Future upstream releases will be committed to this repository in the same way.
- The repository will be named: <project>-import
- For example, project bar would be: bar-import
- Our repository will be "based" on the import.
- We will create a branch off of a recent stable upstream release and make our changes there.
- To make future syncing easier, and to make it easier to separate out our bits from upstream, we will rebase. Rebasing is a best-practice for managing upstream sources. For example, the Ubuntu kernel is regularly rebased against upstream. The alternative, merging commits from upstream, results in local changes being interleaved with upstream. Rebasing creates a clean history with local changes appearing after upstream commits.
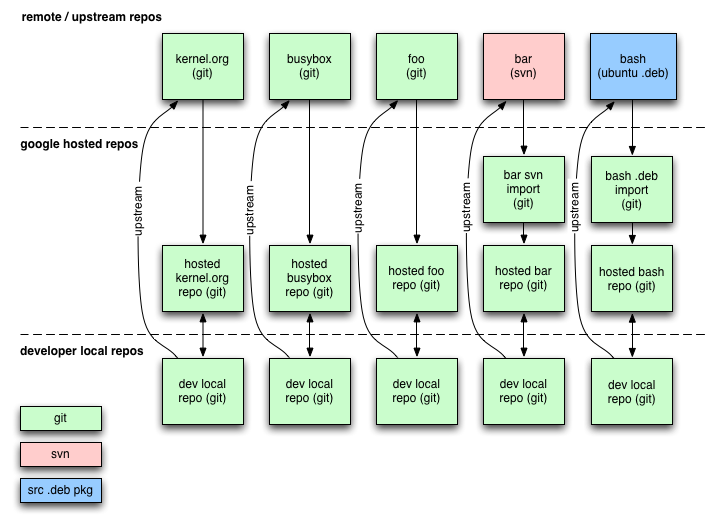
The diagram below shows the flow of code between repositories. Repositories above the top dashed-line are upstream-hosted, the repositories between the dashed-lines are Google-hosted, and the repositories below the lower dashed-line are the user's local checkout. Where upstream is non-Git, we'll create a local Git import tree: "bar svn import" and "bash .deb import" above. The Google repository will be a Git repository based on a particular upstream tag of the upstream Git repository (or our Git import if upstream is not using Git).
Package database
Initially, we will store a README.chromium file in the root directory of the package which will contain the following fields in shell parseable format:
- DESCRIPTION: one-line description of the package
- HOMEPAGE: URL to upstream page (possibly a freshmeat.net page)
- UPSTREAM_REPO: URL for upstream repository
- LOCAL_GIT_REPO: git url for our Git repository
- UPSTREAM_BUGSDB: URL for upstream bug database
- LOCAL_BUGSDB: URL for our bug database for this package
- LICENSE: name of license (we'll need a license database somewhere)
Eventually, we may move to a more sophisticated web-hosted package database like Launchpad. In a web-hosted package database, we could also display derived information like: current Chromium OS version, upstream latest version, and so on.
Sample README.chromium for busybox
DESCRIPTION="Utilities for embeddded systems" HOMEPAGE="http://www.busybox.net" UPSTREAM_REPO="git://git.busybox.net/busybox" LOCAL_GIT_REPO="https://chromium.googlesource.com/external/busybox" UPSTREAM_BUGSDB="https://bugs.busybox.net/" LOCAL_BUGSDB="http://tracker.chromium.org/busybox" LICENSE="GPL-2"
LICENSE_FILE="LICENSE"
Commit log metadata
We want to track where our sources are coming from. The mechanism for doing this will be to recommend that the following metadata be included as part of the commit log:
- Source: Where did this change come from? Google? Ubuntu? kernel.org?
- Commit ID: Git commit id / SVN log number / patch number in package
- Tested status: Leaning on people to describe how they tested a checkin has proved to be extremely effective "social engineering" in other projects
- Upstream status: Tracking upstream status is more difficult as the status will evolve over time. This data may need to be in a separate database, but tying the database into the DVCS will not be simple to keep consistent over Git rebases (which change Git commit IDs).
Code review
Our current code review tool, Rietveld, already supports Git change uploads via update.py. For making it easier to do Git code reviews with Rietveld, we will be using git-cl, . There is also an open-source tool designed specifically for Git code reviews: gerrit. It is a fork of reitveld.
Checkout management
We are using gclient for package checkout management.
References and links
Git tutorial
http://www-cs-students.stanford.edu/~blynn/gitmagic/