HTTP Cache
Overview
The HTTP Cache is the module that receives HTTP(S) requests and decides when and how to fetch data from the Disk Cache or from the network. The cache lives in the browser process, as part of the network stack. It should not be confused with Blink's in-memory cache, which lives in the renderer process and it's tightly coupled with the resource loader.
Logically the cache sits between the content-encoding logic and the transfer-encoding logic, which means that it deals with transfer-encoding properties and stores resources with the content-encoding set by the server.
The cache implements the HttpTransactionFactory interface, so an HttpCache::Transaction (which is an implementation of HttpTransaction) will be the transaction associated with the URLRequestJob used to fetch most URLRequests.
There's an instance of an HttpCache for every profile (and for every isolated app). In fact, a profile may contain two instances of the cache: one for regular requests and another one for media requests.
Note that because the HttpCache is the one in charge of serving requests either from disk or from the network, it actually owns the HttpTransactionFactory that creates network transactions, and the disk_cache::Backend that is used to serve requests from disk. When the HttpCache is destroyed (usually when the profile data goes away), both the disk backend and the network layer (HttpTransactionFactory) go away.
There may be code outside of the cache that keeps a copy of the pointer to the disk cache backend. In that case, it is a requirement that the real ownership is maintained at all times, which means that such code has to be owned transitively by the cache (so that backend destruction happen synchronously with the destruction of the code that kept the pointer).
Operation
The cache is responsible for:
- Create and manage the disk cache backend.
This is mostly an initialization problem. The cache is created without a backend (but with a backend factory), and the backend is created on-demand by the first request that needs one. The HttpCache has all the logic to queue requests until the backend is created.
-
Create HttpCache::Transactions.
-
Create and manage ActiveEntries that are used by HttpCache::Transactions to interact with the disk backend.
An ActiveEntry is a small object that represents a disk cache entry and all the transactions that have access to it. The Writer, the list of Readers and the list of pending transactions (waiting to become Writer or Readers) are part of the ActiveEntry.
The cache has the code to create or open disk cache entries and place them on an ActiveEntry. It also has all the logic to attach and remove a transaction to and from ActiveEntry.
- Enforce the cache lock.
The cache implements a single writer - multiple reader lock so that only one network request for the same resource is in flight at any given time.
Note that the existence of the cache lock means that no bandwidth is wasted re-fetching the same resource simultaneously. On the other hand, it forces requests to wait until a previous request finishes downloading a resource (the Writer) before they can start reading from it, which is particularly troublesome for long lived requests. Simply bypassing the cache for subsequent requests is not a viable solution as it will introduce consistency problems when a renderer experiences the effect of going back in time, as in receiving a version of the resource that is older than a version that it already received (but which skipped the browser cache).
The bulk of the logic of the HTTP cache is actually implemented by the cache transaction.
Sparse Entries
The HTTP Cache supports using spares entries for any resource. Sparse entries are generally used by media resources (think large video or audio files), and the general idea is to be able to store only some parts of the resource, and being able to serve those parts back from disk.
The mechanism that is used to tell the cache that it should create a sparse entry instead of a regular entry is by issuing a byte-range request from the caller. That tells the cache that the caller is prepared to deal with byte ranges, so the cache may store byte ranges. Note that if the cache already has a resource stored for the requested URL, issuing a byte range request will not "upgrade" that resource to be a sparse entry; in fact, in general there is no way to transform a regular entry into a sparse entry or vice-versa.
Once the HttpCache creates a sparse entry, the disk cache backend will be in charge of storing the byte ranges in an efficient way, and it will be able to evict part of a resource without throwing the whole entry away. For example, when watching a long video, the backend can discard the first part of the movie while still storing the part that is currently being received (and presented to the user). If the user goes back a few minutes, content can be served from the cache. If the user seeks to a portion that was already evicted, that part the video can be fetched again.
At any given time, it is possible for the cache to have stored a set of sections of a resource (which don't necessarily match any actual byte-range requested by the user) interspersed with missing data. In order to fulfill a given request, the HttpCache may have to issue a series of byte-range network requests for the missing parts, while returning data as needed either from disk or from the network. In other words, when dealing with sparse entries, the HttpCache::Transaction will synthesize network byte-range requests as needed.
Truncated Entries
A second scenario where the cache will generate byte-range request is when a regular entry (not sparse) was not completely received before the connection was lost (or the caller cancelled the request). In that case, the cache will attempt to serve the first part of the resource from disk, and issue a byte range request for the remainder of the resource. A large part of the logic to handle truncated entries is the same logic needed to support spares entries.
Byte-Range Requests
As explained above, byte-range requests are used to trigger the creation of sparse entries (if the resource was not previously stored). From the user point of view, the cache will transparently fulfill any combination of byte-range requests and regular requests either from sparse, truncated or normal entries. Needless to say, if a client uses byte-range requests it should be prepared to deal with the implications of that request, as having to determine when requests can be combined together, what a range applies to (over the wire bytes) etc.
HttpCache::Transaction
The bulk of the cache logic is implemented by the cache transaction. At the center of the implementation there is a very large state machine (probably the most common pattern in the network stack, given the asynchronous nature of the problem). Note that there's a block of comments that document the most common flow patterns for the state machine, just before the main switch implementation.
This is a general (not exhaustive) diagram of the state machine:
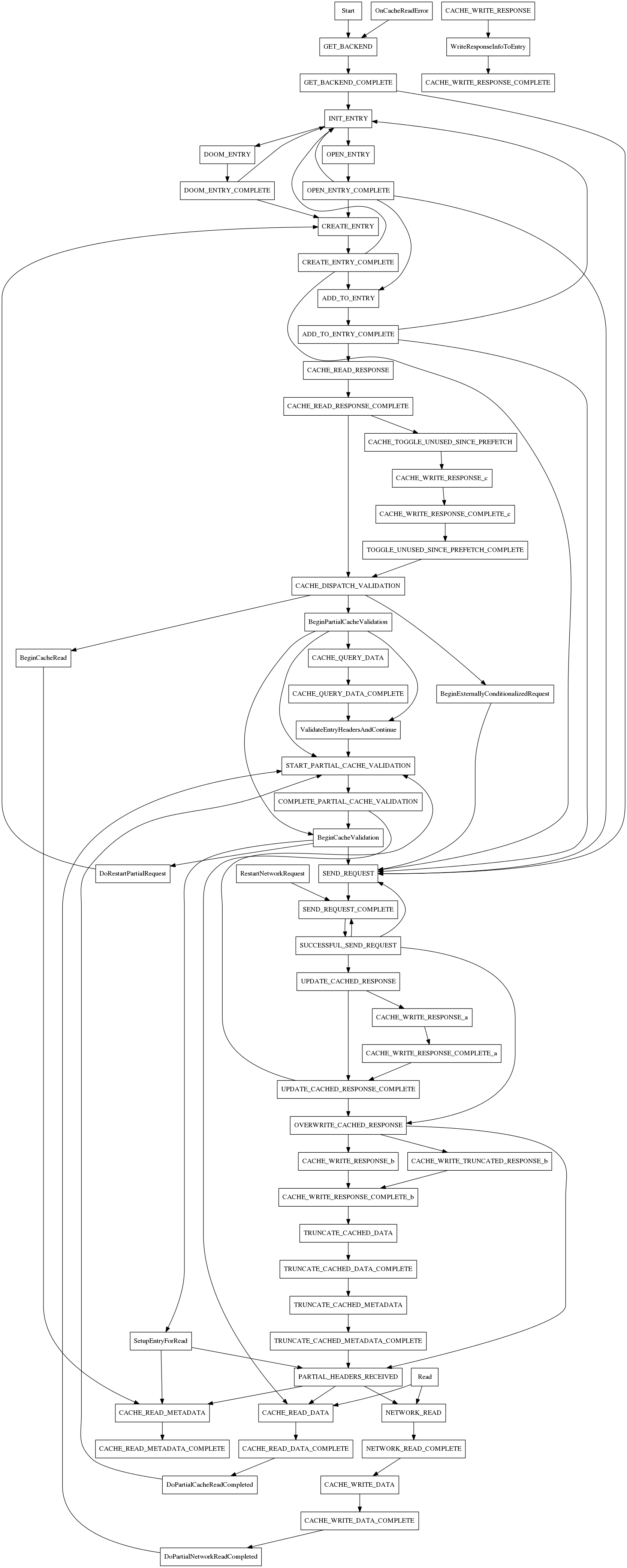
This diagram is not meant to track the latest version of the code, but rather to provide a rough overview of what the state machine transitions look like. The flow is relatively straight forward for regular entries, but the fact that the cache can generate a number of network requests to fulfill a single request that involves sparse entries make it so that there is a big loop going back to START_PARTIAL_CACHE_VALIDATION. Remember that each individual network request can fail, or the server may have a more recent version of the resource... although in general, that kind of server behavior while we are working with a request will result in an error condition.