Telemetry: Record a Page Set
We record page sets so we control network conditions and other changes in the live sites, leading to more stable benchmarks.
Write a page set
Before you can record a page set, you need to write it! If you want to record a pre-existing page set, you can skip this step.
Page sets are located in
tools/perf/page_sets.
A simple page set with one URL looks like:
from telemetry.page import pagefrom telemetry.page import page_setclass MyPageSet(page_set.PageSet): def __init__(self): super(MyPageSet, self).__init__( user_agent_type='desktop', archive_data_file='data/my_page_set.json', bucket=page_set.PUBLIC_BUCKET) self.AddPage(page.Page( name='example', url='http://example.com/', page_set=self))
Telemetry spoofs Chrome's User-Agent field, and user_agent_type tells it
whether to use a desktop, mobile, or tablet user agent. We generally only use
one recording for all platforms.
The archive_data_file contains metadata about which pages are stored in which
archive files. You need to specify its location, and it will be generated when
recording the page set.
Note that the naming convention of page set file is to lowercase & underscore class name, e.g. MyPageSet should be stored as my_page_set.py.
Choosing a bucket
Telemetry has three Cloud Storage buckets you can put page sets in.
page_set.PUBLIC_BUCKET == 'chromium-telemetry'page_set.PARTNER_BUCKET == 'chrome-partner-telemetry'page_set.INTERNAL_BUCKET == 'chrome-telemetry'
Google wants to avoid legal issues with distributing third-party content, so to
be safe, most recordings of websites on the public web go in
PARTNER_BUCKET, which is accessible by Googlers and certain Google partners.
Recordings of Google-properties on the public web can go in PUBLIC_BUCKET, and
recordings of unreleased or internal Google websites go in INTERNAL_BUCKET.
If you require access to the PARTNER_BUCKET, submit a ticket here.
Recording and Uploading
You can record and upload a page set or benchmark using the update_wpr tool (recommended!). Alternatively, follow the instructions below.
Record a page set or benchmark
Use the record_wpr script to record a page set or benchmark (preferred). Your
command will look something like this:
src$ tools/perf/record_wpr --browser=(release|system) <page_set_name or benchmark name>
For example, to record the top25_smooth.py page set, specify top25_smooth_page_set:
src$ tools/perf/record_wpr --browser=system top25_smooth_page_set
To update the recording for only some pages in the page set, use
--story-filter. This command will record only Wikipedia pages:
src$ tools/perf/record_wpr --browser=system --story-filter=wikipedia top25_smooth_page_set
record_wpr generates a few files:
- A
.wprfile containing the recorded data. This file is hidden fromgit status, which we'll explain next. - A
.wpr.sha1file containing the SHA1 hash of the.wprfile. - A
.jsonfile containing metadata about which.wprfiles store which URLs.
Upload the recording to Cloud Storage
To avoid bloating everyone's Chromium checkouts, we avoid committing the large
.wpr files to source control. Instead, we upload them to Cloud Storage and
download them as needed. If you just want to use your recording locally, you can
skip this step.
If you haven't already, you may need to set up Cloud Storage.
To do this, check in only the .sha1 and .json files. When you run git cl upload, a PRESUBMIT script will check whether you have already uploaded the
recording to Cloud Storage.
To upload your new recording to cloud storage, use the following command, as referenced in the presubmit warning:
src$ depot_tools/upload_to_google_storage.py --bucket (chromium-telemetry|chrome-partner-telemetry|chrome-telemetry) tools/perf/page_sets/data/my_page_set_000.wpr
Moving recordings between Cloud Storage buckets
Sometimes the addition or removal of pages changes the permission of the page set, or the page set archives are in the wrong bucket. To move files between buckets, use this command:
src$ tools/telemetry/cloud_storage mv tools/perf/page_sets/data/my_page_set_*.wpr (public|partner|google-only)
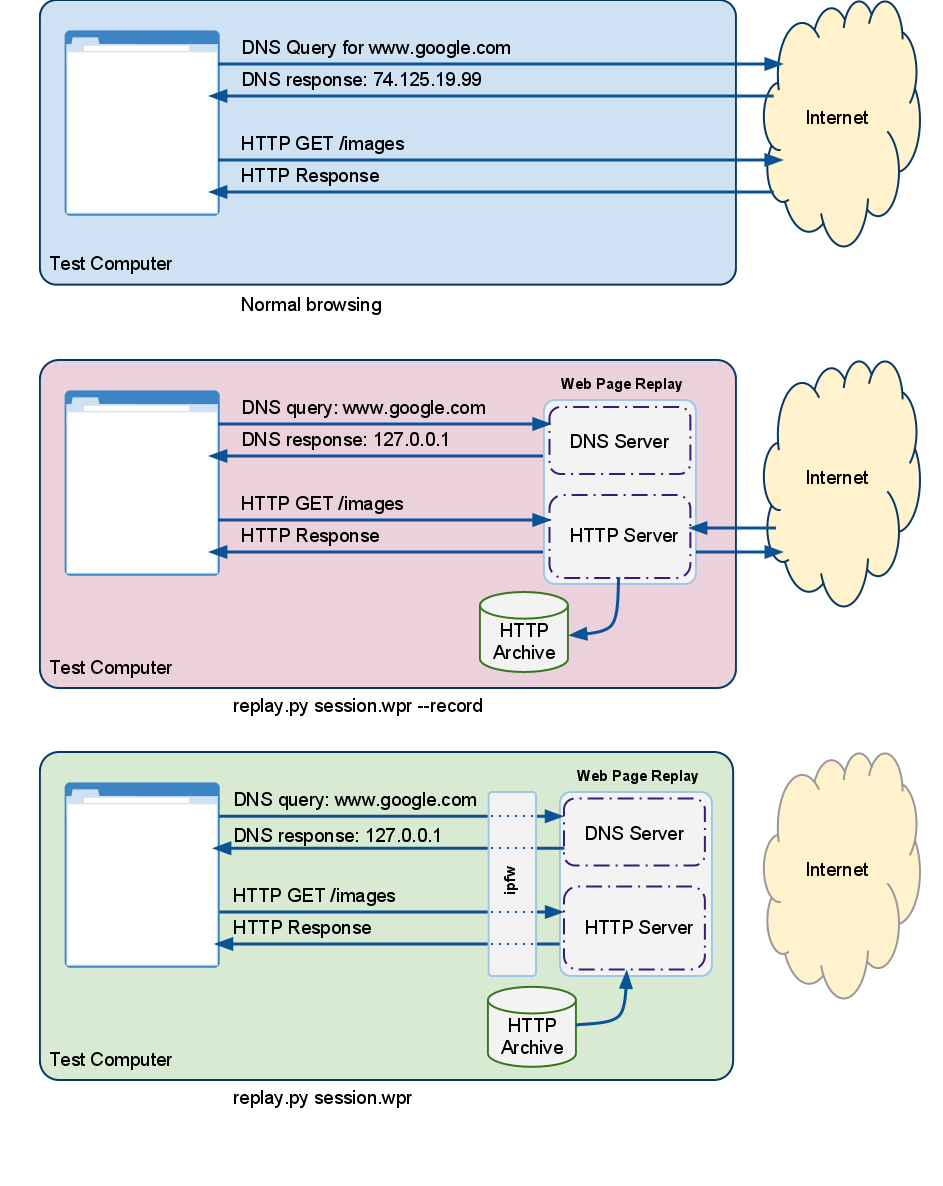
What is Web Page Replay?
Web Page Replay is a service that allows us to capture and store HTTP requests and responses.