Autoupdate Details
Abstract
This document describes details about how the autoupdate system works. For a high-level view of autoupdate, and information about the filesystem, see File System/Autoupdate.
The autoupdate system provides bit-for-bit-exact in-place filesystem updates with file-level binary diffs.
Goals
- Updates should be as small as we can reasonably make them.
- An update must result in a root-filesystem partition in which each disk block is exactly (bit-for-bit) as specified by the OS vendor, so that the update can be signed on the server (for verified boot).
- Updates must be applied in place, so that many delta updates can be installed without rebooting. For example: if a user is booted into version N, and N+1 is released, the user downloads the (N→N+1) update and installs. If the user is still booted into N when N+2 comes out, then the user downloads the (N+1→N+2) update and in-place installs it over N+1.
Overview of the install procedure
The client will have a partition (which we'll call the "install partition") on which to install a delta update. This partition will already contain some version of the operating system.
The client will contact the autoupdate server to request an update, specifying the version number of the system installed on the install partition. The server may provide the client with a delta update which the client will download.
The delta update file contains an ordered list of operations to perform on the install partition that will take it from the existing version to the new version.
Overview of the delta update file format
Note: The destination partition is composed of 4K blocks.[1]
The update file is an ordered list of operations to perform. Each operation operates on specific blocks on the partition. For each operation, there may be an optional data blob, also included in the update file.
The types of install operations are:
- Copy: copy some blocks in the install partition to other blocks in the install partition. This can be used to move a block to a new location, or to copy a block to temporary storage; for more information, see the example below.
- Bsdiff: read some blocks into memory from the existing install partition, perform a patch (binary diff) using the attached data blob, and write the resulting updated blocks to specified blocks in the install partition. (See below for more details.)
- Replace: write the attached data blob to specified blocks in the install partition.
- Replace_bz: B-unzip the attached data blob and write the result to specified blocks in the install partition.
A traditional diff update to a file (using bsdiff) works like this: the old file and the patch file are read into memory. Next, a patch operation is performed in memory, resulting in the new file being in memory. Finally, the new file is written to disk. We modify that operation slightly. We tell the patch program that the old file is the install partition. However, rather than have the program read the entire partition into memory, we tell it which blocks to read. Then the patch operation is performed in memory. Finally, the result is written directly to the install partition, but not at the beginning of the device: we will tell the program which blocks to write the result to.
Generating delta update files
This section describes how the OS vender creates an update file.
The update file format will be:
- Magic number ('CrAU')
- Version number
- Eight bytes for protobuf length
- The protobuf
- Collection of data blobs
- EOF
The protobuf is a series of instructions that the client must perform in order.
Note: To specify a set of blocks, we use an extent, which is simply a contiguous range of disk blocks. For example, rather than specify blocks {10, 11, 12, 13, 14, 15, 17, 18}, it can be simpler to specify { (10, 6), (17, 2) } (a list of extents). message Manifest { message InstallOperation { enum CompressionType { COPY = 0, // file is unchanged; just move data blocks BSDIFF = 1, // Read source data blocks as old file, included binary blob is diff, output to new blocks REPLACE = 2, // Output included binary blob to new blocks REPLACE_BZ = 3 // Bunzip binary blob into new blocks } uint64 blob_offset; // if present, the offset in the update image of the binary blob for this file uint64 blob_length; // if present, the length of the binary blob message extent { uint64 offset; // in blocksize uint64 length; // in blocksize } repeated extent input_extents; repeated extent output_extents; } repeated InstallOperation install_operations; }
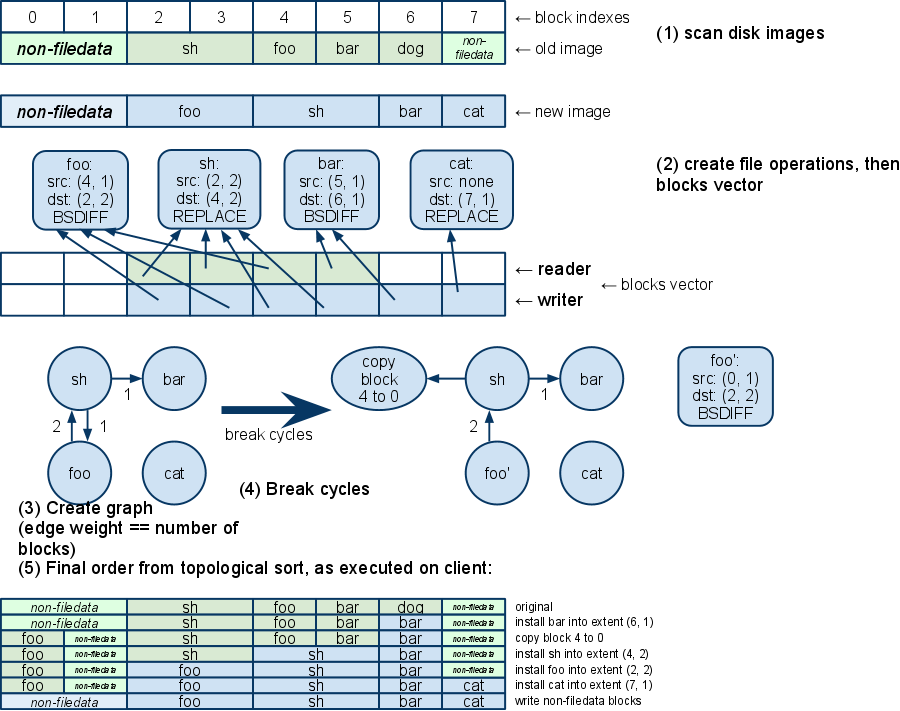
To generate a delta update, we iterate over each regular file on the new filesystem. We get an ordered list of all datablocks in the file, then store those in a File struct: struct Extent { uint64 start; uint64 length; } struct File { string path; // path within the filesystem vector<Extent> dst_extents; // ordered list of all extents on the new filesystem vector<Extent> src_extents; // Applies only for COPY and BSDIFF enum CompressionType; // one of: COPY, BSDIFF, REPLACE, REPLACE_BZ }
Note: eventually, each File object will be converted into an InstallOperation message in the protobuf. For each file, we look for the optimal way to compress it. If the file has changed, then we compare the sizes of the binary-diff, uncompressed, and bzip options, and we pick whichever yields the smallest file size.
We then create a vertex in a graph for each File object. Alongside the graph, we also create a vector to represent each block in the install partition: struct Block { File* reader; File* writer; } vector<Block> blocks; // length is the size of the install partition
We then go through each block in each File object. For each block, we set the reader and writer parameters of the blocks vector.
Next, we iterate through the blocks array, and for each block with a different reader and writer (which are both non-null), we create an edge in the graph from the writer to the reader. An edge in the (directed) graph points to a file operation that must complete before the edge's source file operation starts. Thus, we are trying to ensure that if a block is both read and written by different file operations, the block is read before it's written. The edge represents blocks in the graph, so the edge's weight is the number of blocks.
At this point, we are likely to have a graph with cycles. We must break the cycles. We find the cycles with Johnson's circuit finding agorithm (PDF) and Tarjan's strongly connected components agorithm. For each cycle, we find the lowest-weight edge and cut it[2]. We cut an edge as follows: create a new node that represents an operation of copying some extents to scratch space. We then make the edge's source node point to the new node. We also modify the cut edge's destination node to read from the scratch space rather than from the blocks represented by the edge we're cutting.
Here's an example of cutting an edge to break a cycle. Operation A reads block 3 to write block 4. Operation B reads block 4 to write block 10.
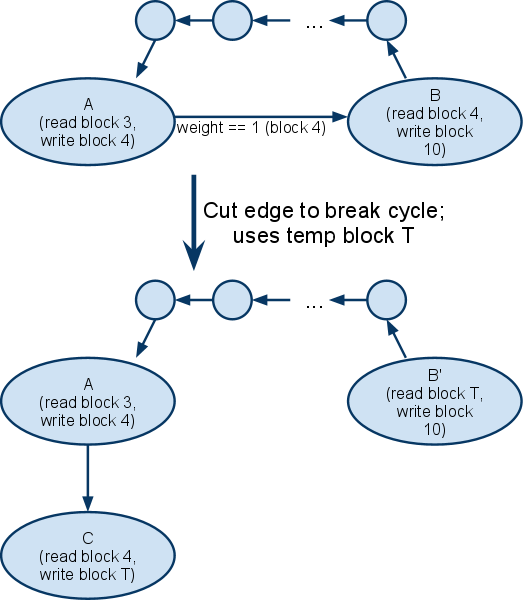
Once the cycles are broken, we can use a topological sort to order all the nodes. Then we convert each node to an InstallOperation and add it to the Manifest structure. If the client were to download and install the Manifest at this point, all the blocks that contain filedata would be set correctly. However, we also need non-filedata blocks to be set correctly. To handle non-filedata blocks, we create a single final InstallOperation of type REPLACE_BZ which writes to all extents that don't contain filedata. The attached data blob contains the bzip2-compressed data to go into those blocks. In practice, this takes up about 2 megabytes compressed.
Example
Streaming
Because the protobuf (which lists all operations) occurs at the beginning of the file, the update doesn't need to be saved to disk. It can be applied while streaming from the server.
We do need to make sure that the update is signed by the OS vendor. We can begin to apply the update and not mark it bootable until after the delta update signature is verified.
Alternatives considered
The solution presented here is not the only one we considered, but it is the only one we've found that gives the best compression ratio in practice. Other solutions considered were:
-
Delta-compress the entire partition Bsdiff can't delta-compress the entire partition because its memory requirements are too high. During patching, it needs enough memory to store the original and new files, which in our case could have been over 1 gigabyte. However, another delta compression program, Xdelta, uses a sliding window. In practice, this resulted in poor compression. On a test corpus, the diff was hundreds of megabytes.
-
rdiff Rdiff works by storing only changed blocks in the delta file. It uses a sliding window so that blocks don't need to be aligned. When pointed at the testing corpus, an rdiff delta of the entire partition was 104M, well above the roughly 10M the proposed algorithm takes for the same corpus. In the future, we might consider using rdiff-style (that is, rsync-style) delta compression at the file level. We could drop that in alongside bsdiff in the future.
Footnotes
[1] Some of these blocks contain file-data and some contain other data (metadata, for example). Since we are using ext4, which (at the time of writing) doesn't support fragments, we know that a block cannot contain file data for more than one file: a block either contains file data for one file or no files. [2] In our tests, with the greedy agorithm (cut an edge in each cycle as it's found), we cut about 28 MB worth of edges, which seems reasonable. Enumerating all cycles and cutting no edges, we found over 5,000,000,000,000,000 cycles, so it's absolutely infeasible to consider all cycles before making cuts. To cut cycles more efficiently, though, we might consider more than 1 cycle before making cuts (perhaps 1000 cycles or so).