Chrome OS User-Land Boot Design
Introduction
This document gives an overview of the design of user-land boot processes for Chrome OS based systems. It covers what happens after /sbin/init first starts execution, until all services in the system are ready.
Chrome OS Core uses Upstart for its /sbin/init package. Readers of this document should have some basic familiarity with Upstart concepts, such as the syntax of job configuration files, and Upstart events, such as starting and started. An in-depth presentation of Upstart concepts is available in the Upstart Cookbook.
Readers should also have some understanding of Linux file system management concepts, like mounting and creating file systems.
If you want to go deeper and read the source code, you’ll need some understanding of shell programming and ChromiumOS security mechanisms (minijail, SELinux). If you want to understand the initialization of an individual package, you’ll need to be familiar with that package’s basic operations. None of these topics is covered in this document.
Summary of Boot Flow
Phases of Boot
Boot est omnis divisa in partes tres.
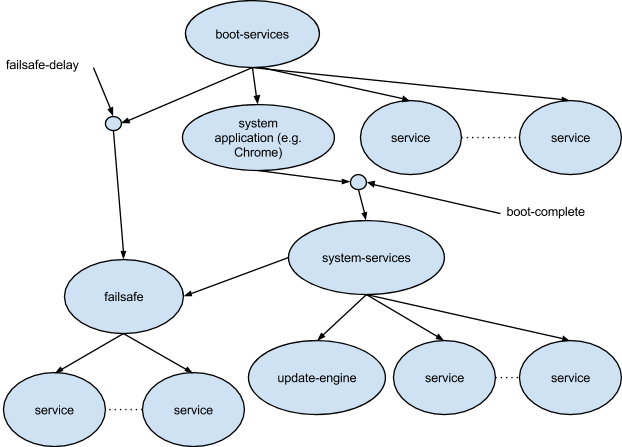
The diagram above shows an outline of the Chrome OS Core boot flow. Boot divides into three sequential phases with four publicly defined Upstart events:
| startup | Basic Services | Initialization of basic services needed by the rest of the system. |
| started boot-services | System Application | Initialization of the system application and other services critical to the product’s UX |
| started system-services | System Services | Initialization of all other services. |
| started failsafe | Failsafe Service | The failsafe job is guaranteed to start even if the system application fails. |
Basic Services Startup
“Basic services” are the indispensable services required by the system application and the rest of the system. Most services cannot operate until these basic services are running normally.
At the end of basic services startup (that is, when Upstart emits started boot-services), the following services are guaranteed available:
- A file system generally conforming to the Linux FHS.
- A logging service compatible with rsyslogd.
- Device hotplug detection. User input devices or other devices necessary to the system application will be detected, with modules loaded. Detection of devices deemed non-critical may be delayed until after the system application starts.
- dbus-daemon.
Note that jobs that run during this phase must by their nature work in an environment where the services above may not be available. At the beginning of this phase, there is no guarantee of writable storage; jobs cannot log messages, write any files, or read files outside of the root filesystem. Additionally, device availability is not guaranteed in all cases; devices may not be initialized, and their drivers may not even be loaded.
System Application Startup
Chrome OS Core is predicated on the existence of a single, dedicated application that is central to system startup. For Chrome OS, that application is the Chrome browser. The Chrome OS sources are structured to allow a platform to choose to use a different system application.
The system application starts in parallel with various critical services. Typically, “critical” means that the system application expects the service to be present, or that the user would perceive the system as not functional without it. For example, in Chrome OS these services include:
- A network.
- The cryptohome daemon.
- System power management.
The system application receives special treatment in the boot flow. The application is responsible for emitting the event which starts the boot-complete job, which allows system services startup to begin. The system application is responsible for this for two reasons:
- Delaying non-critical services allows the system application to start faster.
- If the application fails during startup, the absence of running system services can be used to detect the failure.
For Chrome OS, boot-complete starts when the Chrome browser has displayed the initial login screen.
System Services Startup
This phase of boot includes anything not required in the earlier phases of boot. Generally, all jobs in this phase run in parallel. Because the system is considered already booted, this phase is not performance critical.
After the started system-services event, services can rely on the following:
- All services required after started boot-services are available.
- The udev events for all devices that were present at boot have been processed.
- The system application is available.
By design, system services only start if the system application announces its successful initialization. For most services, this is sufficient: without a system application, the system is in a failed state and many services have no useful purpose. However some services may require that they start eventually, even if the system as a whole has failed. To support this requirement, a service can depend on the started failsafe event. After started boot-services, the failsafe-delay job starts a 30 second timer. The started failsafe event occurs at the earlier of started system-services or the expiration of the timer.
Failsafe jobs are commonly used in test and development images for services necessary to debug or recover from failures. Some examples:
- The openssh-server job, which allows logging in via ssh.
- The udev-trigger job, which can sometimes be needed to detect and configure a network device.
Filesystem Initialization and Layout
Creating the Stateful File System (the chromeos_startup script)
At startup, there is no writable file system storage available. During basic services startup, the script chromeos_startup is responsible for mounting file systems, and creating the basic directory hierarchy. The script is invoked from the startup job, which starts with the startup event emitted by /sbin/init at the start of the userland boot process.
The script creates missing directories and mount points as necessary. This is done to support re-creating the filesystem after stateful wipe, and also to protect the filesystem from inadvertent damage. Below is a list of the principle directories, listed in the order they’re processed.
- /tmp - mounted as a tmpfs filesystem
- /sys/kernel/debug - mounted as a debugfs filesystem.
- /mnt/stateful_partition - mounted as an ext4 file system from GPT partition #1 (but for factory images, a tmpfs file system is used instead).
- /home and its subdirectories - created as necessary; /home itself is a bind mount on /mnt/stateful_partition/home
- /var and /home/chronos - mounted as described below under Encrypted Stateful.
- Subdirectories of /var - created as called for by the Linux FHS.
- /usr/local - This directory is only mounted for developer and test systems. The directory is a bind mount over /mnt/stateful_partition/dev_image.
Encrypted Stateful
As a security measure to protect private data, the portions of the stateful partition under /var and /home/chronos are mounted from an encrypted blob stored in the stateful partition. The encrypted storage is kept in /mnt/stateful_partition/encrypted. Mounting and unmounting the encrypted data is handled by the mount-encrypted command.
Not all Chrome OS Core platforms use this feature: The feature requires a TPM to be effective. Moreover, the feature presupposes some specific privacy requirements. For Chrome OS, these requirements apply; they may not be applicable on all platforms. When the feature is not used, /var and /home/chronos are simple bind mounts.
Special Boot Flows
Chrome OS Core supports a number of special boot flows, many of which are designed to handle system behaviors across multiple boots. This includes special cases for installation, recovery, and update.
Boot Alert Messages
Some special flows involve presenting simple messages to the user prior during basic services startup. All such flows are detected and handled from chromeos_startup. The flows involve one of two use cases:
- During stateful wipe, a message specific to the specific wipe use case will be presented.
- From time to time, an update may contain new firmware for the device. These updates must be performed at the start of the first boot with the new update.
Because these messages are presented during basi services startup, a special script called chromeos-boot-alert is used to accommodate the restricted operating environment:
- The X server is not running. The script uses ply-image to write directly to the frame buffer.
- The chromeos-boot-alert script must wait for the boot splash screen animation to complete in order to guarantee exclusive access to the frame buffer.
- The script must select a localized message text based on the user’s default locale.
Stateful Wipe (a.k.a. “Powerwash”)
In certain boot cases, chromeos_startup must erase and re-create the stateful partition. The script triggers stateful wipe for one of three conditions:
- The stateful partition failed to mount, or a bind mount on the stateful partition failed.
- Wipe requested at the previous shutdown. The script will wipe the
stateful partition if a file named factory_install_reset is present
in the root of the stateful filesystem at boot time. This method is
used for two use cases:
- Factory wipe. At the end of the manufacturing process, the device wipes the stateful partition in preparation for boxing and shipment.
- Power wash. The user can request a wipe for purposes of restoring it to a clean state.
- Wipe after changing from dev mode to verified mode, or vice versa. A
file named .developer_mode in the root of the stateful partition
flags whether the system was previously in dev mode:
- If the file is absent and we’re currently in dev mode, we trigger a wipe for the verified-to-dev mode switch.
- If the file is present and we’re currently in verified mode, we trigger a wipe for the dev-to-verified mode switch.
Principally, wiping the stateful partition means re-creating an empty filesystem using mkfs. Prior to creating the file system, the wipe procedure will also erase data in the partition in order to prevent leaking any private data that was present prior to the wipe.
If the wipe procedure is performed while in dev mode, the .developer_mode file will be created after the wipe. This marks that the system has successfully wiped stateful after the conversion to dev mode.
After the wipe procedure is complete, the system reboots; on reboot the system will rebuild directories and mount points in the stateful file system.
Interactions with Install, Recovery, and Update
After new software is installed by chromeos-install (including device recovery), or automatic update, a reboot is necessary for the new software to take effect. The first reboot after installing new software triggers special handling, depending on the specific installation use case.
Rollback Protection After Update
If a catastrophic system failure manifests immediately after an automatic update, Chrome OS Core can detect the failure and roll back to the previously installed software. The mechanism relies on a three-way interaction with the update_engine service, the firmware, and the system application.
Each kernel GPT partition on the boot disk contains three special attributes flags, which the firmware uses to select which kernel to boot. The flags are designated “priority”, “successful”, and “tries”. The firmware selects the kernel based on these flags; the full rules are described in the design document for the disk format. The update_engine service updates these flags with specific values after applying an update, and again with different values after the system boots without failure.
After update_engine has finished downloading and installed a new image, the update’s post-install phase marks the GPT flags for the new kernel to have the highest priority for boot, with “tries” set to 5, and “successful” set to 0. In this state, the partition will be selected by the firmware as the first kernel to boot.
On each boot, the firmware decrements the “tries” setting for the new kernel in the GPT. If “tries” is decremented to 0 and “successful” is never set to 1, the firmware will roll back to the previous working software. To prevent the rollback, the system must mark the kernel as good by setting the “tries” count to 0 and the “successful” flag to 1 sometime after booting.
Chrome OS Core does not automatically mark the kernel good immediately after boot. Instead, when the update_engine service starts, it sets a 45 second timer. When the timer expires, update_engine invokes a script called chromeos-setgoodkernel. That script marks the kernel as good, after which rollback is no longer possible.
The update_engine service depends on started system-services. Consequently, rollback will be triggered if a newly updated image consistently fails in any of the following ways:
- The kernel panics before chromeos-setgoodkernel can run.
- The system hangs before chromeos-setgoodkernel can run.
- The system application crashes before triggering boot-complete.
Note that the user will typically have to forcibly power cycle a unit multiple times in any failure case other than a kernel panic.
A consequence of this design is that if the system application is crashing at startup, the system cannot receive new updates. This is a deliberate design choice: It is not a bug. The rationale is that if a system is failing in this way, rollback is by far the most preferable way to recover. Waiting for an update is unlikely to be useful in most cases:
- If users wait for an update and the next update contains the same bug, that new update will have overwritten the working previous version. In this case, rollback (by far the most preferable option) will be foreclosed.
- It could be days before a problem of this sort can be recognized, diagnosed, fixed, and released. Many users will be unwilling to wait so long.
- Even if users are willing to wait, most of them will not be easily able to determine when a fixed update is available.
- Recovery is likely to be faster than waiting for an update.
Installation and Recovery
The chromeos-install script can be used to install an image from scratch on a device. The end-user recovery procedure is a wrapper around this script. Additionally, developers can run the script manually when they boot a custom image from USB in dev mode. Although the UX in the two cases is quite different, the system state after installation in either case is indistinguishable.
The installation process includes creating a stateful partition file system, similar to the process for stateful wipe. As with stateful wipe, installation is responsible for creating the .developer_mode file when installing in dev mode. Also as with stateful wipe, after rebooting the system will rebuild directories and mount points in the stateful file system.
Stateful Update and Install
For developer and test builds of Chrome OS, substantial portions of the software are installed in /usr/local, a bind mount over /mnt/stateful_partition/dev_image. This content is not delivered via the autoupdate mechanism. Instead, a script called stateful_update is used to update it separately.
The stateful update procedure operates in two stages:
- The script downloads a tar file, and extracts new content for /usr/local and /var into temporary locations in the stateful partition.
- After reboot, chromeos_startup replaces the old directories with the new ones prior to mounting /usr/local.
Chrome OS - Starting Chrome (the “ui” Job)
The Chrome browser is the system application for Chrome OS. The ui job is responsible for starting, managing, and restarting the Chrome OS session_manager process. The session_manager process in turn is responsible for managing the Chrome browser process.
Job Startup Flow
The ui job is responsible for starting session_manager. That program is responsible for the following:
- Starting the X server process in the background.
- Determining Chrome command-line options.
- Initializing environment variables for the Chrome browser process.
- Initializing the system resources (e.g. directories, files, cgroups) needed by the Chrome browser.
- Starting the Chrome browser.
Once Chrome has successfully displayed the initial startup screen, it kicks off the following sequence of events:
-
Chrome calls session_manager’s EmitLoginPromptVisible interface over D-bus.
-
session_manager emits the login-prompt-visible Upstart event.
-
The login-prompt-visible event triggers the boot-complete job.
Handling Chrome Shutdown, Crashes, and Restarts
When a user logs out of Chrome, the browser process terminates normally. In turn, session_manager terminates, which ends the ui job. In normal operation, the ui job must respawn when this happens. However, in the event of a Chrome crash, the automatic respawn logic is more complex than Upstart’s standard respawn behavior. Instead, whenever the ui job stops, a separate ui-respawn job determines what to do according to these rules:
- If the termination was for system shutdown or reboot, don’t respawn and allow the shutdown to proceed.
- If the termination was for a simple log out, respawn the browser unconditionally.
- For most abnormal termination cases, try respawning the browser.
- If an abnormal termination was because session_manager tried to restart Chrome too many times, try rebooting the system.
Special handling for abnormal termination is subject to rate limitations:
- Respawn is limited to no more than 6 times in one minute.
- Rebooting is only attempted if the particular error termination happens more than once in 3 minutes; otherwise it just respawns.
- Reboot is limited to no more than once every 9 minutes.
If a failure isn’t handled by respawning or rebooting, the ui job stops, but the system stays up. The user can manually force power-off, if desired.
Upstart Events During Chrome Startup
Below is a list of various Upstart events triggered by Chrome browser startup, and when they happen:
| starting ui | This first occurs at boot after started boot-services. After boot, the event will re-occur every time after a user logs out, or any time Chrome restarts after a crash. |
| x-started | session_manager emits this event after the X server finishes initializing. This happens after every Chrome restart. |
| login-prompt-visible | session_manager emits this event after Chrome announces that has finished displaying its login screen. This happens after every Chrome restart. |
| started boot-complete | This occurs the first time that login-prompt-visible is emitted after boot. |
| start-user-session | session_manager emits this event after Chrome announces the start of a user session. |
| stopping ui | This occurs whenever a user logs out, if the Chrome browser crashes, or when the system is shutting down. |
Performance Considerations
The Boot Critical Path
Each phase of boot is dominated by one long running step. These steps must run sequentially, so together they make up a critical path. For Chrome OS, these are the longest running steps in the critical path:
chromeos_startup
X server startup until session_manager emits the x-started event.
Chrome browser startup, until login-prompt-visible
Adding time directly to the critical path will result in delaying boot by an equivalent time. Whenever possible, initialization should run in parallel with the critical path.
ureadahead
System startup time is heavily influenced by the wait time required to read data that isn’t yet in the file buffer cache. The ureadahead program can improve boot time by requesting data in advance of when it’s needed, so that boot spends less time waiting for data from the boot device. Some key facts about ureadahead:
- Platforms that want to use this feature must depend on the sys-apps/ureadahead package.
- Platforms that want to use ureadahead must configure some specific kernel tracing features.
- The ureadahead program starts execution when chromeos_startup finishes, and terminates when boot-complete starts. So, ureadahead doesn’t provide any improvement after the system application has finished starting.
- Auto-update removes the ureadahead pack file during its post-install phase. This means that the first boot after an update will be slower because ureadahead must regenerate the pack file.
Impact of Cached Data
During boot, various processes may cache data under /var, in order to make the next time’s startup faster. However, from time to time these cached data may need to be invalidated (i.e. removed), resulting in a one-time slower boot. Below is a list of known caches affecting boot time, and a summary of what causes them to be invalidated.
- The ureadahead pack files - these live under /var/lib/ureadahead. The auto-update post-install phase invalidates the data whenever a new update is ready.
- The xkb cache files - these live under /var/lib/xkb. They’re created as needed during X server startup. They’re removed on the first boot after any update; this happens in src/install-completed.conf in src/platform/installer.
Measuring Performance
There’s a web site for this.
Boot performance is measured by capturing timestamps at specific moments during the boot flow. These are some of the key events reported by the tools:
| pre-startup | seconds_kernel_to_startup | Start of chromeos_startup |
| post-startup | seconds_kernel_to_startup_done | End of chromeos_startup |
| x-started | seconds_kernel_to_x_started | X server startup complete |
| chrome-exec | seconds_kernel_to_chrome_exec | Session manager fork/exec of the Chrome browser process |
| boot-complete | seconds_kernel_to_login | Start of the boot-complete Upstart job |
All of these events are part of the critical path.
Kernel Performance Accounting Anomalies
For kernel startup, capturing a time stamp at the exact moment of some key transitions is inconvenient. The result is that certain events that ought to be ascribed to one phase (e.g. kernel startup) are ascribed to the adjacent phase:
- Kernel startup begins with decompression of the kernel, and starting kernel time accounting. This work takes a few hundred milliseconds, the bulk which is spent on decompression. This time isn’t recorded as part of the seconds_kernel_to_login metric; to observe this time, you have to look at firmware performance numbers.
- Kernel initialization is complete when it hands control to /sbin/init. However, the userland boot flow can’t mark the start time until chromeos_startup has mounted /tmp and /sys/kernel/debug. That work requires a few dozen milliseconds, and is attributed to kernel startup time.
What Matters, What Doesn’t Matter
Not every change to the boot flow matters to boot performance. Changes may happen to flows that run in parallel with the critical path without slowing it down. Even if a change measurably affects boot time, software engineering considerations such as maintainability or readability may matter more than performance. Below are guidelines for evaluating whether a change might impact boot time, and whether the impact is truly significant.
The Critical Path Matters
As noted, time added in sequence with the critical path is time added directly to boot time. When work executes in parallel with the critical path, the boot time impact will be much smaller. In the best case, work in parallel will consume resources that would otherwise be idle, meaning boot time is unaffected. Even if jobs in parallel compete for resources with the critical path, the impact is typically smaller than the total resource requirement of the extra work.
Evaluating Significance
Performance tuning frequently requires trade-offs between a simpler, more maintainable design, and the best possible performance. Moreover, even when tuning doesn’t have a maintenance impact, the cost to make and test a code change may exceed the benefit of the performance improvement. Finally, the boot time numbers tend to very noisy; small changes are likely not to be statistically significant.
Use these rules when evaluating what trade-offs may be necessary for performance:
- Unless you’re making firmware changes (or certain kernel changes), only changes to the seconds_kernel_to_login (a.k.a. boot-complete) event time matter. The intermediate events are there to diagnose problems, not as performance metrics.
- Changes less than 100ms (.1s) are too small to matter to a typical human and too small to be measured reliably. Below this threshold, the only considerations are the basic software engineering considerations of maintainable, easy-to-understood source code.
- Changes more than 250ms (.25s) are significant. Above this threshold, going out of your way to improve performance is justified.
- In between these two thresholds, exercise careful judgment.
Note that these guidelines apply equally to improvements and regressions: Just as 50 ms slower isn’t a regression, 50 ms faster isn’t an improvement.
Design Principles
The principles in this section are meant to improve the maintainability of packages that deliver Upstart jobs.
Put Jobs in the Right Package
An Upstart job should ideally be associated with a specific service, live in the source code repository for that service, and be delivered in the same package as the service. This has multiple advantages:
- Not all services are required on all platforms/products. Keeping the job with the service means the job won’t be present in systems where it doesn’t belong.
- If the service becomes obsolete, the job will go away when the service’s package is deleted.
- The service and the job frequently change together. Keeping them together reduces the number of repositories you have to change.
- Having the job live close to the program it starts makes it easier to read and understand the service as a whole; you don’t have to consult two source repositories at once.
Depend on the Public Events
For Chrome OS Core, there are four public Upstart events with well-defined, stable semantics. In order of preference, from most to least preferred, they are started system-services, started failsafe, started boot-services, and startup. A package that delivers an Upstart job should depend on the most preferred public job that will meet its requirements.
Note that a job should depend on only one of the four events; depending on more than one event is redundant:
- started system-services implies started failsafe.
- started failsafe implies started boot-services.
Other than the four public events, Upstart jobs and events generated by the chromeos-base/chromeos-init package should be considered private to the package, and subject to change at any time. If your job depends on a private event, changes to chromeos-init could cause your job to start at the wrong time, or not start at all.
If your package depends on chromeos-base/chromeos-login, it can also depend on the standard Chrome startup events.
If your package delivers more than one job, it is safe and reasonable for some jobs to depend on others in the same package instead of depending on the public events.
Where possible, jobs should not depend jobs delivered by other packages, because the inter-package coupling can create maintenance hazards. However, if two packages are already coupled for sound technical reasons, it’s reasonable for one of the package to depend on the other’s Upstart jobs. For examples, look at the tree of jobs for starting the network (see init/shill.conf in src/platform/shill) or cryptohome services (see init/cryptohomed.conf in src/platform/cryptohome).
Depend on Jobs, not Events
Generally, start and stop conditions for jobs should be based on job events like started and stopped, rather than starting or stopping jobs with initctl emit, start, or stop. Depending on a job makes it easier to find the sources of events, and trace their flow through the source code.
If you must use initctl emit, start, or stop, follow these guidelines to help readability:
- Comments in the source where initctl emit is called should name what jobs are affected, and how.
- In jobs affected by initctl emit, start, or stop, there should be comments detailing the callers that do the work.
- There should be comments at the call source and/or job destination that explain why the problem has to be solved this way.
- Both the caller and the affected job should be in the same source package.
Create Your Own Storage
If your service requires writable storage (e.g. a directory in /var/lib), your service is responsible for creating the files and directories. Typically, this can happen in a pre-start script in the Upstart job for the service. Work to create this storage should belong to the package that owns the service. The work should not be handled in chromeos_startup, or an Upstart job not related to your package. The work must happen at boot: In general, there is no way to initialize writable storage at build time.
The objective is that if your package isn’t part of a distribution, it shouldn’t create vestiges in the file systems of distributions that don’t need it.
Note that packages can and should rely on directories specified in the Linux FHS. If a location specified in the standard in the standard is missing, code to create it should be added to chromeos_startup.
Runtime Resource Limits
Every service should limit their runtime resource usage whenever possible. Limits are important to help prevent memory or resource leaks in services from freezing the system. Upstart has directives to control these.
Here are the important ones:
oom score: All init scripts need to define an OOM score. See the CrOS OOM document to pick the score.limit as: Set absolute memory limits. Don't try to pick a tight limit -- this is meant to catch processes that have run out of control, so setting a limit that is 5x-10x what is normal is OK.
Navigating the Implementation
Source Code and ebuilds
The table below shows the package names and source code repository paths for key behaviors described in this document.
| chromeos-base/chromeos-init | src/platform2/init | Basic boot flow |
| chromeos-base/chromeos-login | src/platform2/login_manager | Chrome startup |
| chromeos-base/update_engine | src/platform/update_engine | Rollback support |
| chromeos-base/chromeos-installer | src/platform2/installer | Install/Recovery |
| chromeos-base/chromeos-assets | src/platform/assets | Boot message texts |
Simple Upstart Job Recipes
Simple one-time script
You need to run a short script once after boot. You don’t care about running the command if the system application fails at startup.
Pattern your job after this:
start on started system-services
script
# … initialization commands
end script
Simple daemon
You need a daemon to start after boot. If the daemon dies it should restart. The daemon stores working data in a directory under /var/lib.
Pattern your job after this:
start on started system-services
stop on stopping system-services
respawn
pre-start script
mkdir -p /var/lib/my-daemon
end script
exec my-daemon
Many daemons require expect fork or expect daemon in addition to respawn. Consult your friendly neighborhood Upstart guru for advice.
Failsafe service
You have a service that’s needed for administrative or debug access to your device. Your service can start after the system application, so that it won’t slow down boot. However, if the system applications fails, your service is vital to connecting to the failed unit in order to repair or debug it.
Pattern your job after this:
start on started failsafe
stop on stopping failsafe
respawn
exec my-important-administrative-daemon
Service Required by the System Application
When your system application starts, it connects to a service provided by a separate daemon that must be started in its own job. The system application can’t finish initialization without this second service, and will wait until it’s ready.
Pattern your job after this:
start on started boot-services
stop on stopping boot-services
respawn
exec my-important-daemon
Initialization That Blocks Chrome Startup
You have system-wide initialization that must finish before Chrome can start. No other services have a dependency.
Pattern your job after this:
start on starting ui
task
script
# perform your important initialization here
end script
File System Initialization Required by Multiple Services
You have a service that provides a shared resource in the file system (e.g. a directory, a named FIFO, etc.). You need to make sure that the file system resource is created before any service depending on started boot-services.
Pattern your job after this:
start on starting boot-services
task
script
create-my-important-resource
end script
FAQ
Creating a New Chrome OS Core Platform
Q: What Upstart jobs must my platform supply?
A: The platform must supply a boot-complete job conforming to certain basic requirements.
Q: What are the requirements for the boot-complete job?
A: The job must have a start stanza that will start once the system application is up and providing service. Your platform can define “providing service” any way it wants, but generally the job shouldn’t start until these criteria are met:
- Performance critical startup is complete.
- An ordinary user will perceive the device as fully functional.
For reference, on Chrome OS, after stripping out comments and boilerplate, the boot-complete job consists of just this one line:
start on login-prompt-visible
Q: How do I provide a boot-complete.conf for my board?
A: boot-complete.conf is provided by virtual/chromeos-bootcomplete. You can override this virtual in your board overlay.
Q: How do I disable/enable the encrypted stateful feature?
A: The feature is enabled by default. To disable the feature, set USE=”-encrypted_stateful”.
Adding a New Service
Q: What repository should hold my Upstart job?
A: Ideally, the job should live in the source repository for the service it starts. If there’s no such repository (e.g. your service is an upstream package), create a new package to install the job. For an example, see the chromeos-base/openssh-server-init package.
Q: When should I use start on started system-services?
A: This is the preferred way to start any job that should run once at boot time. However, if your job is important to starting the system application, you may need to depend on boot-services instead.
Q: When should I use start on started failsafe?
A: Use this for a job that can start after the system application, but that must run eventually even if the system application never starts. This start condition is most useful for services that are needed to debug or recover a failed unit.
Q: When should I use start on started boot-services?
A: Use this when the job must start in parallel with the system application. This is typically required for one of these reasons:
- The job is required before the system application can provide service, or
- Until the job runs, the user may perceive the system as not functional.
Note that by running in parallel with the system application, the job may slow down system boot.
Q: Can my service just use start on startup?
A: Most services should avoid doing this, because of the restrictions it imposes:
- There is no writable storage: directories like /tmp, /home and /var will not be mounted.
- System logging is not available; the only way to debug is to write messages to a TTY device.
- Not all devices will be available under /dev; no udev rules for any devices will have run.
References
Upstart reference: http://upstart.ubuntu.com/cookbook/
The ureadahead man page: http://manpages.ubuntu.com/manpages/precise/man8/ureadahead.8.html