Unified Sync And Storage Overview (Needs update)
What is it?
Unified Sync and Storage (USS) is a refactoring of Sync internals and services that depend on Sync.
The goal of the refactoring is to address the following existing issues:
Address sync data consistency issues that stem from the lack of
transactional consistency between Sync database and native model specific
storages.
Reduce disk and memory usage by Sync data on the client.
Improve parallelism, eliminate thread contention on shared objects (Sync
Directory).
Reduce code complexity.
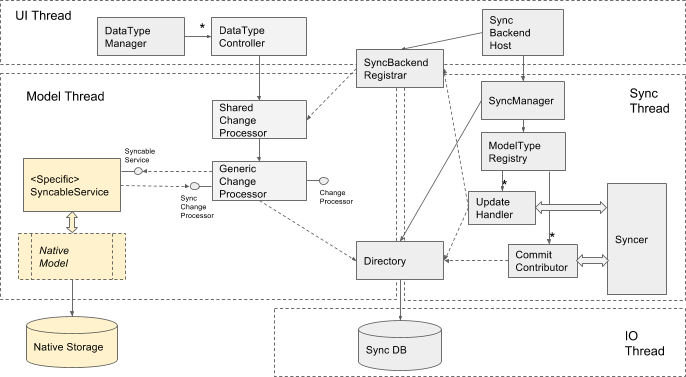
Currently, all synced data is stored locally in two different locations (see the first diagram below). The first is the native storage, which exists regardless of whether or not sync is turned on. Examples of the native model storage are Preferences JSON file, Bookmarks file, Autofill SQLite Database. The second is Sync DB, a file in SQLite format, which is managed entirely by Sync. Sync DB contains snapshots of synced data and sync specific metadata.
On Sync startup the database is loaded into the Directory - the in-memory repository of all sync data and metadata. The directory is shared between threads and provides transactional semantics for all changes triggered by local model changes as well as changes coming with server updates. The directory provides a decoupling between the model facing part of Sync Engine and the server facing part of the engine running on the sync thread. For example, if there is a local change, it first gets updated in the directory, marked as unsynced, then sync thread separately reads it from the directory when it is time to commit changes to the server. This makes the directory the centerpiece of the current design. But at the same time this makes the directory the the main bottleneck - an exclusive access to the directory is needed for any operation with it. Also since the directory keeps all the data and sync metadata readily available in memory there the scalability of this approach is limited to tens of thousands of entries.
The idea is to decentralize Sync storage and to shift the storage responsibility, at least conceptually, from Sync engine to Sync clients e.g. native models that own the actual synced data. The core Sync components don’t have to know anything about the storage, they just pass messages containing sync data asynchronously all the way to data type specific sync service (the adapter between Sync engine and the native model). The sync service encapsulates the storage capable of storing sync metadata along with the model data. The storage implementation is responsible for ensuring consistency of the model data with sync metadata.
That doesn’t mean every native model has to roll out its own storage. Sync team will provide a generic levelDB based storage that should satisfy requirements for most simple data types that want to leverage the simple “syncable storage” API.
More complex data types can roll their own sync metadata storage implementation on top of their already existing storage mechanism or on top of an in-memory object model. In most cases it would be a thin adapter over the existing storage that allows Sync to bundle Sync metadata with the corresponding data entities or to store Sync metadata side-by-side (e.g. in a separate table in case of SQLite DB). The expectation is that in most cases no or very little changes would be needed to the existing native model and/or storage implementations. The customization would be handled by the model specific sync service.
High Level design comparison
The two pictures below illustrate the current Sync design (the first picture) and compare that to the proposed USS changes (the second picture).
Current
Proposed changes
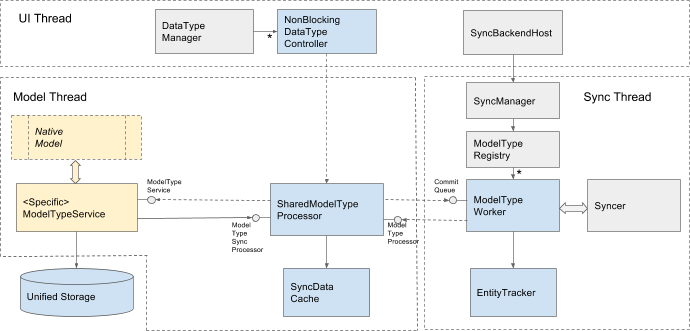
Color coding:
| Grey | Existing Sync components shared between the existing implementation and USS implementation. |
| Blue | New USS specific components (typically one instance per native data type). |
| Yellow | Native data type specific components. The most typical case of data type implementation is shown, but a more complex custom implementation is possible. |
The most significant difference between the current Sync design and USS is where the storage for sync data and metadata is.
With the USS proposal there is no centralized in-memory Directory and Sync DB. The responsibility for providing the storage for sync metadata is shifted to the native model, the storage is encapsulated by the model specific implementation of DataTypeService.
The in-memory repository of sync entities is handled by a generic type agnostic sync processor component - SharedDataTypeProcessor. This component is roughly a counterpart of SharedChangeProcessor and GenericChangeProcessor in the current design.
DataTypeService works in conjunction with SharedDataTypeProcessor. The pair is designed to be fairly decoupled from the rest of Sync engine and to handle native model changes even when the rest of Sync isn’t running. Here is how responsibilities are divided between them:
| Model specific DataTypeService (the service) | SharedDataTypeProcessor (the processor) |
Having a separate copy of synced data is no longer necessary except for holding on to it for a short time in memory, only for in-flight entities that are being committed to the server or passed back with a server update. The transactional semantics of the directory as a way to pass the data between the model and the sync thread is replaced with asynchronous messaging with sync data payloads.
USS reuses a significant part of the current design. There are two integration points where USS specific components plug into Sync architecture:
On the UI thread sync datatype configuration and management is done through data type specific instance of NonBlockingDataTypeController (USS specific implementation of DataTypeController). It has the same responsibilities as regular DataType controllers in the current implementation:
Abstracts USS datatype management from the rest of Sync engine.
Handles USS datatype initialization, configuration and state transition
logic during startup and shutdown.
Handles activation and deactivation of the datatype with Sync backend.
DataTypeWorker (the worker) is USS specific implementation of Sync engine’s UpdateHandler and CommitContributer interfaces. The key difference between this component and currently existing counterparts is that the existing implementation propagates sync changes through the shared directory by writing updates to the directory and querying uncommitted local changes from the directory. The USS based implementation achieves the same by exchanging the data across the thread boundary with the processor. The worker provides a short term in-memory cache for pending committed entities waiting for the next scheduled sync cycle or for the network connection to the server. If the application terminates before successfully committing pending entities to the server, the processor running on the model, based on the last saved snapshot of the metadata, can still determine all the entities with unfinished commit and re-commit them through the engine pipeline.
DataTypeWorker has the following responsibilities:
Provides integration of USS datatypes on Sync backend side:
Generates commit messages to the server
Processes update messages from the server
Generates nudges to the sync scheduler.
Handles two-way communication with the processor running on the model thread
(receives commit requests, posts back commit confirmations and updates).
Handles data encryption.
Tracks in-flight entities and resolves some simple conflicts.
The rest of Sync backend (shown as Syncer on the diagram) remains mostly unchanged from the current design.
Patterns of data type implementation on top of USS
### Typical - for data types with a simple model.
This pattern is close to the original USS proposal. It is usable for cases where the entire model is fully syncable meaning that:
All model entities are syncable
All data fields of each entity are syncable
An entire model entity data can be translated to
[sync_pb::EntitySpecifics](https://code.google.com/p/chromium/codesearch#chromium/src/sync/protocol/sync.proto&q=EntitySpecifics&sq=package:chromium&type=cs&l=66)
and back without losing any state.
This pattern would be most suitable for brand new data types that don’t have their own storage mechanism. The consistency is ensured by the Sync provided levelDB based storage that holds both native model data and Sync metadata.
The typical implementation is based on a fairly generic base implementation of DataTypeService that would implement all of the logic for hosting the storage, accessing and saving all model data and sync metadata, handling interaction with the Sync Engine, etc. The service surfaces a simple storage API for the native model to get, put, delete entities, and to notify about remote updates. All of the syncing is happening transparently to the model.
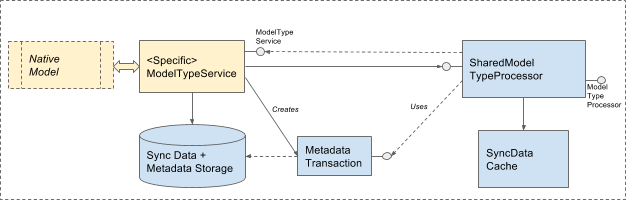
2. Trivial - special case of Typical pattern without the native model
Data type examples: Sessions, DeviceInfo.
This is a further simplification of the Typical pattern where there is no native model and everything is fully contained inside the data type specific DataTypeService.
3. Custom with unified storage.
Data type examples: Bookmarks, TypedURLs.
This pattern is for complex data types with existing storage mechanism that can accommodate storing additional Sync metadata. The consistency is ensured by custom, data type specific sync metadata storage implementation that piggybacks the already existing native storage mechanism.
For example, for Bookmarks data type, the metadata storage could leverage the existing bookmark’s MetaInfo container to bundle arbitrary Sync metadata along with bookmarks.
For TypedURLs data type, sync metadata could go into a separate table in the existing SQLite database. The consistency would be ensured by leveraging the already existing open transaction mechanism.
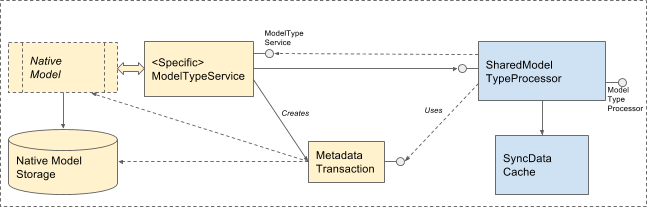
4. Custom with separate sync storage.
Data type examples: Passwords.
This pattern is for complex data types with existing storage mechanism that can’t accommodate storing additional Sync metadata.
While this pattern can’t guarantee the high level of consistency that the unified storage can provide, it should still be able to improve the situation compared to the current Sync implementation and to leverage some other benefits of the refactoring like the storage isolation, smaller memory usage, better parallelism.
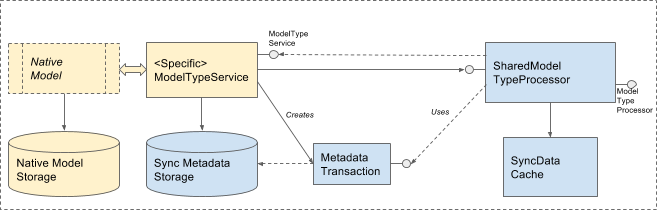
In this case Sync metadata is stored on the side, in Sync provided levelDB storage which is hosted by the data type specific implementation of DataTypeService. There should be no need to duplicate the actual data in the metadata storage except may be for in-flight data for a small number of entities.
Because there are two side-by-side storages, a custom model specific association would need to be performed when the storage is loaded to detect and handle any discrepancies. The association / synchronization of the two storages would be done entirely at the service level. Just like in other cases, as far as Sync core components are concerned, the Sync metadata storage mechanism should be opaque to the engine and handled completely by the data type specific DataTypeService implementation.
Implementation Notes
USS architecture shares a number of components with the current Directory based Sync Engine architecture and should have no problem running side-by-side with it. Existing Sync datatypes might be migrated to the new architecture one by one. The migration should be transparent to Sync Server and to other clients running older versions of Chrome.
The plan is to start by implementing all USS specific Sync Engine components as well as the generic levelDB based storage.
Then migrate one trivial datatype such as DeviceInfo and one complex datatype such as Bookmarks. Based on the experience migrating these two datatypes we'll decide what datatypes to migrate next and in which order.
Summary
Let’s review each USS refactoring goal and how it is going to be addressed.
Data Consistency
The main reason for inconsistency is lack of transactional coordination between Sync writing sync data to its own database and the native models persisting data into their own storages.
USS avoids this problem altogether by eliminating the Sync’s private storage and shifting the metadata storage to the unified storage. The data type specific service (DataTypeService implementation) is responsible for keeping the sync metadata in sync with the data changes. In some cases the metadata consistency with the data is guaranteed by owning the storage implementation and in some cases that is provided by piggybacking on the native storage implementation and understanding how a particular native storage persisting works (see the implementation patterns section above).
Another source of inconsistency is delayed startup of Sync or turning Sync off temporarily (which is possible on mobile platforms). The complete configuration of Sync may sometimes be blocked on network connectivity and gives a user plenty of time to make local changes that remain untracked by Sync.
USS avoids this problem by allowing the change processor component (SharedDataTypeProcessor) to handle local changes and keep updating related sync metadata regardless of whether the rest of Sync engine is up and running. This is possible because the storage of sync metadata doesn’t depend on the Sync backend anymore.
Disk and memory usage optimization
Sync DB maintains two copies of synced data plus some sync specific metadata for each synced entity. The two data copies of data are:
Local entity data received from or propagated to the native model.
Remote entity data received from or committed to the server.
These copies are needed to guarantee that sync metadata is always consistent with the data that Sync operates on(which can get out of sync with the native model as explained above), to ensure that Sync can resume incomplete operations across Chrome restarts, and to enable conflict resolution when the local changes collide with server updates.
Sync loads the entire database into memory at startup which includes all the metadata and two data copies per entity. As a result of recent Directory copy-on-write memory usage optimization Sync attempts to share the two copies if they contain identical data. However even with the optimization the extra memory usage is still on the order of several KB per entity.
With USS implementation the plan is to stop keeping any extra copies of sync data on disk or in memory except for short term caching of in-flight entities, e.g. the entities waiting to be committed or applied to the model. The metadata maintained by Sync should allow it to recover from unexpected termination and to redo unfinished operations from scratch, including re-fetching from the model and re-committing items that need to be committed and re-requesting update from the last known progress marker.
Improved parallelism, reduction of thread contention.
The main source of thread contention is exclusive access to Sync Directory shared between all threads. It is fair to say that most of the time only one thread at a time can perform sync operations. Other threads are often blocked waiting to enter the directory read or write transaction.
With USS implementation there is no locking on the directory access. Each datatype has its own asynchronous messaging pipeline.
Code Complexity
The proposed design in general has a fewer number of layers. The centerpiece between the model thread and sync thread is eliminated. The whole layering complexity around the directory access with the transactions, directory persistence, integrity checking, etc is completely eliminated. Each syncable datatype becomes mostly independent from any other datatype. The type specific complexity that is still present in the directory implementation should be moved all the way to type specific DataTypeService implementation. The core of Sync engine should become more or less a streamlined messaging pipeline with conflict resolution logic.
At the same time the complexity of conflict resolution might increase due to asynchronous nature of USS pipeline and lack of a well defined transaction.