Omnibox: History Provider
One of the autocomplete providers for the omnibox (the HistoryQuickProvider, HQP for short) serves up autocomplete candidates from the profile's history database. As the user starts typing into the omnibox, the HQP performs a search in its index of significant historical visits for the term or terms which have
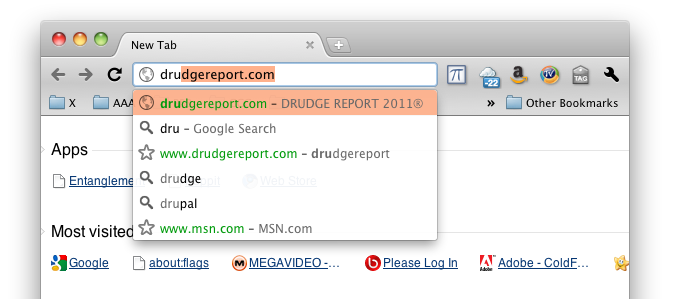
been typed. The resulting candidates are scored and a limited number of only the most relevant matching URLs visited are presented to the user. For example, imagine the user has visited drudgereport.com frequently and has started to type 'dru' in the omnibox. They will be presented with autocomplete suggestions as shown in the screenshot to the right. Substring matching is also performed. The drudgereport.com suggestion will also be made if the user types 'rep', though the
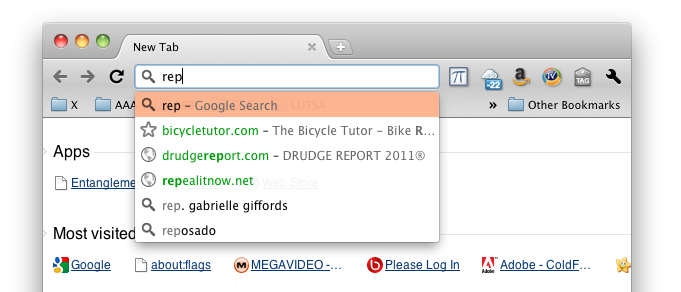
result will not be scored as highly and is likely not to be the top-most suggestion, as shown in the screenshot on the left. Multiple terms also work. drudgereport.com will be one of the top suggestions, in this example, when the user types 'dr re', 're dr', and similar partial words. The URL of the visited page is indexed and searched. As of Chrome 15, the page title is also indexed and searched.
Objectives
The HQP is intended to very quickly provide scored autocomplete suggestions from a limited subset of all known historical URL visits. The specific objectives are:
- Provide results in 20 ms or less.
- Provide the top 3 best matches for the terms typed by the user.
- Provide results as each character in the terms has been typed.
- Accommodate all browser supported languages.
- Consider only URLs:
- for which the URL was specifically typed into the omnibox OR
- which has been visited at least at least 4 times OR
- has been visited within the last 72 hours.
- Match against the URL and/or the page title.
- Match against partial strings.
- Match against one or more terms.
- Match against internal substrings (i.e. do not limit matches to start-of-string).
- Provide results immediately upon browser startup.
- Do not degrade startup and shutdown times.
- Require reasonable memory resources.
Approaches Considered
Three primary alternatives were considered:
- Perform queries against the history database as the user types search terms.
- Create a custom in-memory subset of the history database and perform queries against this custom database as the user types search terms.
- Create a custom in-memory index of the history database and perform queries against this index as the user types search terms.
Option #1 is far too slow and does not satisfy other requirements such as partial string matches. Also, properly handling word-breaks for all languages is extremely difficult. Option #2 is much faster but still does not satisfy the language and partial string match requirements. Option #3 is more complex to implement but satisfies all requirements. Caching of the in-memory data structures is required in order to meet startup/shutdown requirements. Further, in order to minimize an impact from writing the cache at shutdown and whenever updates to the index meant refreshing the cache a simple-minded transaction log is required. Within Option #3 are other considerations specifically as they relate to the cache:
- During startup, the index must be built as quickly as possible (see Objectives 9 and 10). A cache helps satisfy these objectives. Unfortunately, in the absence of a cache a complete query of the history database must be performed in order to rebuild the IMUI; that database can be quite large, reaching tens of thousands of URL visits. Fortunately, a rebuild of the IMUI should rarely be necessary. The bulk of the pressure during startup will be the speed of loading the cache and repopulating the IMUI data structures.
- During shutdown, the IMUI must be cached as quickly as possible. On desktop systems, users are intolerant of an application taking more than a few milliseconds to shut down and get out of the way. A complete write of the IMUI data to the cache at shutdown may be quick enough to meet shutdown time requirements. If those requirement cannot be met, then an approach where the cache is constantly kept up-to-date may be required.
- During operation, it's important to keep the on-disk cache up-to-date in case the browser unexpectedly shuts down.
In summary, a cache will be required as well as some mechanism for keeping that cache up-to-date as the user visits sites and as old, stale visits are removed from the index. For a detailed discussion of the HQP caching implementation please see Caching.
Components
There are two primary components to the history autocomplete provider: the HistoryQuickProvider (HQP) and the InMemoryURLIndex (IMUI).
HistoryQuickProvider
The HistoryQuickProvider, an AutocompleteProvider, is a client of the InMemoryURLIndex. HQP, when asked for autocomplete candidates, marshalls the search term (or terms) and asks the IMUI to provide scored and sorted matches for that term (or terms). HQP then composes a list of AutocompleteMatches from the IMUI results and notifies the autocomplete system that results are available. The design of the HQP follows the typical AutocompleteProvider pattern and is not further discussed here.
InMemoryURLIndex
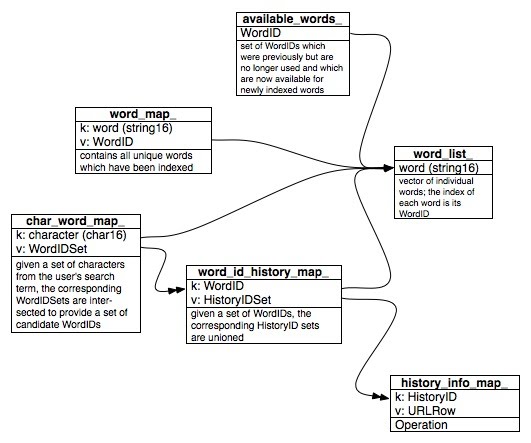
All of the interesting stuff is in the IMUI. In essence, the text of the URL and the page title for all qualified history items (URL visits from the history database) are broken down into individual words and characters and inserted into in-memory data structures with a reference to the original history item. Here is a diagram of these data structures:
Indexing
During a build of the index, and whenever the user visits a site, the URL and the page title for that visit are added to the index. Here's how it works:
For this example, let's use "http://www.americanentertainer.com/xj20gg1Z.html" with a page title of "Recent Movies".
For each qualifying URL visit:
- Insert an entry into the history_info_map_ for the HistoryID of the URL visit.
- The URL and page title are broken down into individual words:
- http www americanentertainer xj 20 gg 1 Z html recent movies
- For each word:
- Append the word to the word_list_ with the insertion index serving as the WordID.
- Insert the word into the word_map_ with its WordID.
- Add the HistoryID for the URL visit to the HistoryIDSet of the word_id_history_map_ item corresponding to the WordID, adding a new map entry if necessary.
- Break the word down into a set of unique, individual characters.
- For each character:
- Add the WordID for the word containing the character to the WordIDSet of the char_word_map_ item corresponding to the character, adding a new map entry if necessary.
The available_words_ list contains the WordIDs for entries in the word_list_ which are no longer in use. This occurs when URL visits no longer qualify for use by the HQP and one or more words of the URL or its page title are no longer referenced by any of the indexed URL visits. Maintaining this list prevents an ever growing word_list_ (a poor-man's garbage collection).
Searching
The following diagram demonstrates what occurs in the HQP as the user types into the omnibox. In this case, the user has type the four characters: d r u d.
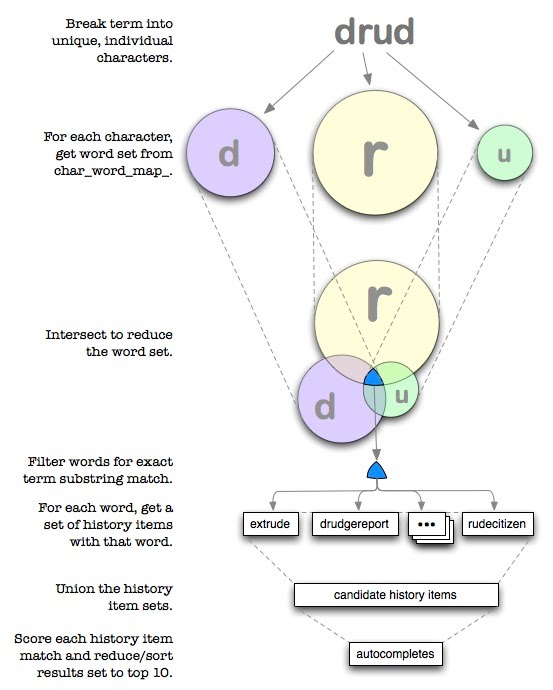
Whatever the user types may constitute multiple search terms, either deliberately or not. The following are examples of multiple search terms:
| what's in the omnibox | how it's broken down |
| fox542steal | fox 542 steal |
| amer spec | amer spec |
| google.com/search?source=ig&hl=en | google com source ig hl en |
To Do
Immediately
- Update the threading model for cache file reading
- Use SQLite as the caching mechanism.
Future
- Record HQP statistics (qualifying visit count, size of cache and transaction files, etc.).
- Validate the scoring algorithm through user feedback.
- See if there is a way to offer in-line autocomplete results for multiple-term searches.
- Determine if the full cache ought to be occasionally written, clearing the transaction file.